 MRC Cognition and Brain Sciences Unit
MRC Cognition and Brain Sciences Unit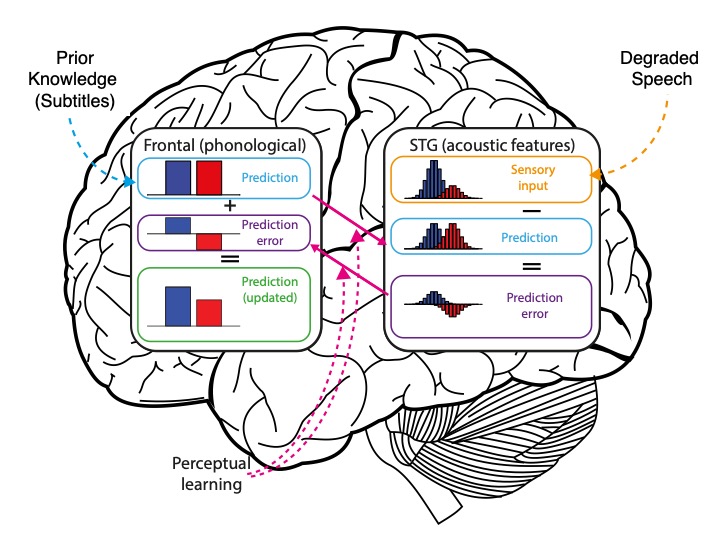
In our everyday life, we often encounter speech that is hard to hear and understand. This can be due to the noise of a busy pub, hearing someone with an unfamiliar accent, or for speech heard over a bad telephone line. All of these problems are exacerbated for people with impaired hearing; the most common sensory impairment in ageing individuals.
One thing that helps when watching TV is to use written subtitles that accompany difficult-to hear speech. Our research has shown that written subtitles not only enhance understanding and make speech sound clearer, they also help listeners to ‘tune-in’ so that they can better understand degraded speech even without subtitles. Measures of brain activity before, during and after this form of perceptual learning showed that subtitles help by reducing brain responses associated with “prediction error”. A simple model of these processes helps explain the brain mechanisms responsible for learning to understand degraded speech.
This work with healthy volunteers hearing degraded speech has implications for people with hearing loss who are fitted with a cochlear implant in later life. Cochlear implants are prosthetic devices that restore functional hearing to otherwise deaf individuals. However, they provide a form of speech that is degraded and initially hard to understand. It can take months for a new cochlear implant user to get the best out of the degraded sounds that they hear. Subtitles, and other forms of visual support like lip-reading help cochlear implant users adapt to their implant. We are now beginning to understand the brain processes that support this simple intervention.
You can hear example audio clips from this project here: https://soundcloud.com/user-359399217/this-simple-trick-can-help-you-make-sense-of-degraded-speech
Or listen to an interview on the BBC Radio 4 programme “Inside Science” with senior author Dr Matt Davis, starting at 21 minutes: http://www.bbc.co.uk/radio/player/b07414kl
The published paper is: Sohoglu, E., Davis, M.H. (2016) Perceptual learning of degraded speech by minimizing prediction error. Proceedings of the National Academy of Sciences of the USA, 113 (12), E1747-E1756. https://www.pnas.org/content/113/12/E1747


